蒙特卡罗、动力学蒙特卡罗、分子动力学三者的异同解析

本文先讨论MD和Metropolis MC,暂不讨论Kinetic Monte Carlo (KMC)。这是因为传统的MD和MC更具可比性(为简单起见,这里MC就是指狭义上的使用Metropolis算法的蒙特卡罗,而这里谈到的MD仅限于平衡态的MD模拟,暂不讨论非平衡态的NEMD)。
两种方法产生的初衷都是为了计算统计力学里的系综平均:假设系综所对应的相空间的概率分布为P(p,q)(p为动量,q为坐标),那么对于任意平衡态热力学量M,它的系综平均<M>可以表示为
![]()
说得更直白一点,传统的MD和MC基本上是在干同一件事:算积分。只不过最早的MD是在微正则系综(NVE系综)里算积分,而最早的MC是在正则系综(NVT系综)里算积分。
先说MC
众所周知,正则系综里相空间的概率分布就是玻尔兹曼分布

 是配分函数,
是配分函数,  ,这个相空间概率分布就是下图所示,其实就是个高斯分布。
,这个相空间概率分布就是下图所示,其实就是个高斯分布。
知道了概率分布,那么正则系综中任意平衡态热力学量M的系综平均<M> 就是下面这个积分
对于上式中的积分,绝大多数情况下是没有解析解的,因此只能通过数值求解。最简单粗暴的用蒙特卡洛方法求解上式积分的方法就是在整个积分区域上均匀地随机打点,求得每一点处的M(p,q)e-ßH(p,q)值,然后对所有点求和再除以配分函数即可。例如对于一维线性谐振子,我们可以如下在相空间上均匀地打点
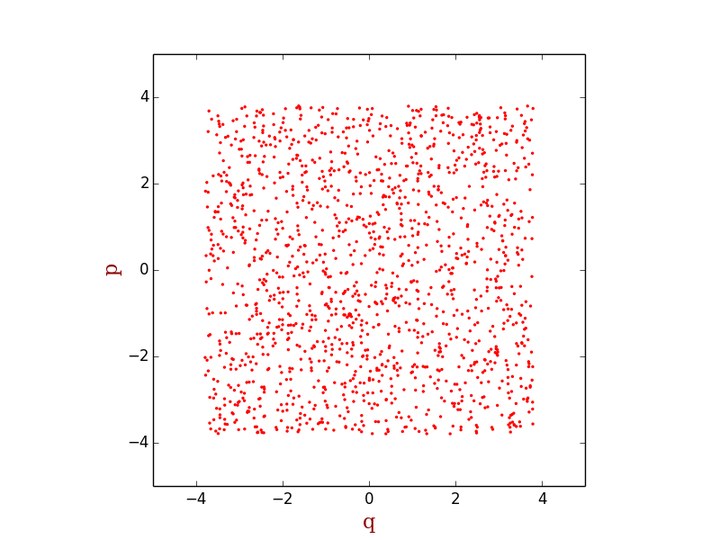
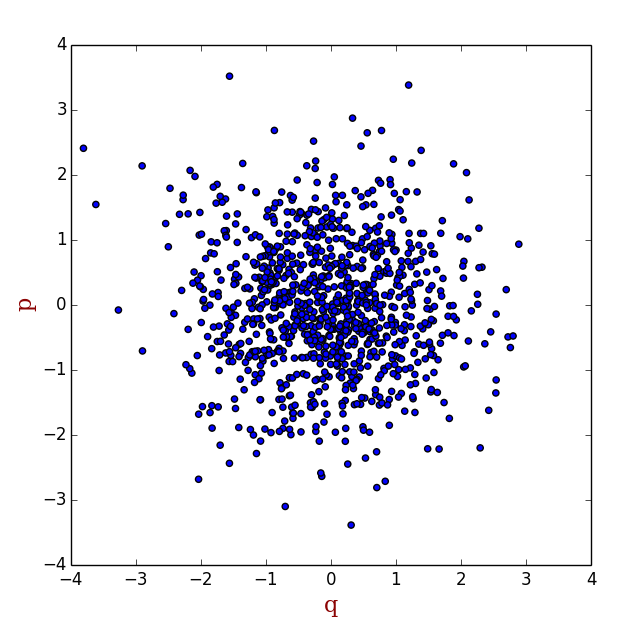
这种算法,的确非常简单,但效率很低。因为位于相空间中e-ßΗ的值非常小的区域,系统处于这个区域的概率非常低,也就是说这些区域大体上来说对系综平均<M> 的贡献是非常小的,然而在采样过程中,由于我们是随机均匀打点,这样e-ßΗ的值非常小的点和e-ßΗ的值非常大的点的权重是一样的。换句话说,我们浪费了不少时间在那些权重很小的点上。那么是否有这样算法,能够使产生的点的分布符合玻尔兹曼分布,也就是说,在e-ßΗ的值非常小的区域少打点,在e-ßΗ的值非常大的区域多打点(如下图所示),然后把每一点处的M值相加,就能得到我们需要的系综平均呢?Metropolis算法就是为了实现这样的目标产生的。关于Metropolis算法的细节,我不在这里展开,很多书籍里都有描述。
再说MD
 那么热力学量M在微正则系综里的系综平均<M> 就是
那么热力学量M在微正则系综里的系综平均<M> 就是 其中V是积分的区域,也就是当能量为E时系统所占据的相空间。拿一维线性谐振子作为例子,当能量为E时其在相空间中区域对应于下图中的圆环,那么这个系综平均就是根据上式在对应于能量为E的圆环区域上进行积分。MD所做的,就是让粒子跑遍这个圆环上的每一个点(历经各态,ergodicity),把每一点上M的值加起来求平均,得到的就是系综平均(time average equals ensemble average, this is what we call ergodicity)。
其中V是积分的区域,也就是当能量为E时系统所占据的相空间。拿一维线性谐振子作为例子,当能量为E时其在相空间中区域对应于下图中的圆环,那么这个系综平均就是根据上式在对应于能量为E的圆环区域上进行积分。MD所做的,就是让粒子跑遍这个圆环上的每一个点(历经各态,ergodicity),把每一点上M的值加起来求平均,得到的就是系综平均(time average equals ensemble average, this is what we call ergodicity)。
综上,MD和MC都可看作是为计算系综平均的采样方法。采用Metropolis算法的MC不局限于在正则系综里的采样,可以应用于其他系综,比如NPT和巨正则系综。至于微正则系综,理论上也可以使用Metropolis算法,只是由于各个态之间能量相等,概率也相等,这时使用Metropolis算法不能起到加速采样的作用,等于白用。同样地,MD的采样也不局限于微正则系综,当把一个孤立体系和一个恒温器(thermostat)或者恒压器(barostat)耦合起来,就可以进行正则系综或者NPT系综里的模拟。当然,如果耦合的恒温器或者恒压器是以extended Lagrangian形式实现的话(比如Nose-Hoover Thermostat),广义上来讲MD模拟还是可看作在一个大的微正则系综中进行。
MD和MC的比较
KMC
Kinetic Monte Carlo(KMC)和主要模拟平衡态性质的MD和Metropolis MC相差就比较远了,它主要模拟系统随时间的演化而非平衡态性质。KMC的基本思想是把整个系统划分成若干个态(state),并获得态与态之间单位时间的跃迁几率(这个可以通过分子模拟或者过渡态理论来计算),然后通过具体的算法决定每一步往哪一个态跃迁,就可以模拟系统在各个态之间随时间演化。我没有做过KMC的研究,并不太了解KMC的算法,仅仅粗略看过一两篇用KMC模拟扩散的文章。以下的例子是我粗浅的理解,可能不太准确。
我们想用KMC模拟粒子在二维晶格上的扩散,并求出扩散系数。假定在单位时间步长内,粒子只能跳到它最相邻的格点。如图所示,粒子某时刻处于A格点,那么粒子下一时刻只有可能跳到B,C,D,E格点,单位时间内粒子从A跳到这些格点的跃迁几率分别为rAB,rAC,rAD,rAE。结合这些跃迁几率,KMC的算法就可以通过生成随机数来决定粒子下一步所在的格点。在模拟足够长时间后我们可以算出粒子的均方位移(mean square displacement, MSD), 均方位移和扩散系数成正比关系,因而可以求出扩散系数。
当粒子只能在一维情况下运动(即只能从A到B或者从A到D),并且rAB=rAD, 这种情况下KMC其实就是在模拟一维随机游走(random walk)。
本文经授权转载自知乎刘书乐老师的回答:Metropolis蒙特卡罗方法、动力学蒙特卡罗方法、分子动力学方法这三种模拟方法有何特点与差异?
材料牛编辑整理。
材料人重磅推出材料计算解决方案,可提供包括第一性原理、分子动力学、流体力学等方面的计算模拟服务。如有需求,欢迎联系微信号:iceshigu,或点击链接提交需求,微信端可扫以下二维码提交。





文章评论(0)